Learn Before
BERT-base Hyperparameters
The BERT-base model is configured with a specific set of hyperparameters that determine its overall size and architectural capacity. These key settings include a hidden size () of 768, a model depth of 12 Transformer layers (), and 12 attention heads (). Together, this structural configuration produces a model containing a total of 110 million parameters.
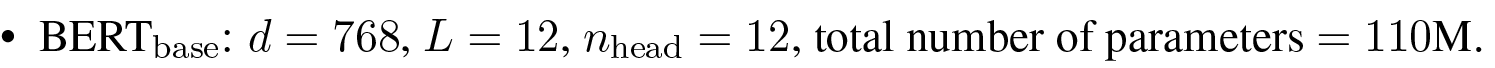
0
1



Tags
Ch.1 Pre-training - Foundations of Large Language Models
Foundations of Large Language Models
Foundations of Large Language Models Course
Computing Sciences
Related
BERT-base Hyperparameters
BERT-large Hyperparameters
Challenges of Large-Scale BERT Models
A team is developing a large, bidirectional, transformer-based language model. Their initial design has 12 processing layers, a hidden state dimension of 768, and 12 attention heads. To significantly increase the model's capacity, they are considering two potential modifications. Which single change would result in a greater increase in the model's total number of parameters?
Model Selection for a Resource-Constrained Application
You are presented with two common configurations for a bidirectional, transformer-based language model. Match each model scale to its corresponding set of architectural hyperparameters.
Learn After
A standard language model architecture with approximately 110 million parameters is built using a specific combination of layers, hidden size, and attention heads. Which of the following configurations correctly represents this model?
Hyperparameter Configuration for a Standard Language Model
A standard language model architecture with approximately 110 million parameters is defined by a specific set of hyperparameters. Match each hyperparameter with its correct value for this model.