Learn Before
Data Point as a d-dimensional Vector
Combining Token and Positional Embeddings
In sequence models like the Transformer, the final input representation for a token is created by summing its semantic embedding with an embedding that encodes its position. The formula is , where is the token embedding vector for the -th token, is the positional encoding vector for position , and is the resulting combined vector. This process allows the model to use information about the order of tokens.
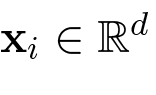
0
1
10 days ago



Tags
Ch.2 Generative Models - Foundations of Large Language Models
Foundations of Large Language Models
Foundations of Large Language Models Course
Computing Sciences
Related
Combining Token and Positional Embeddings
Positional Encoding Vector